In recent years, Large Language Models (LLMs) like GPT-3, LLaMA, and others have revolutionized the way we interact with technology. These models can generate human-like text, answer questions, and even assist in coding. However, most of these models are hosted on cloud servers, which can raise concerns about privacy, latency, and cost. What if you could run an LLM locally on your own machine? Enter OLLAMA, a powerful tool that allows you to install and run LLMs locally.
But now Deepseek R1 is here!
In this article, we’ll walk you through the process of installing an Deepseek R1 locally using OLLAMA. Whether you’re a developer, researcher, or just a tech enthusiast, this guide will help you get started. We’ll also include some images to make the process easier to follow. Let’s dive in!
What is OLLAMA?
OLLAMA is an open-source framework designed to simplify the process of running large language models locally. It provides a user-friendly interface and handles the complexities of model management, making it accessible even for those who aren’t machine learning experts. With OLLAMA, you can download, configure, and run LLMs on your local machine without needing to rely on cloud-based services.
Why Run an LLM Locally?
- Privacy: Running a model locally ensures that your data never leaves your machine, which is crucial for sensitive applications.
- Cost-Effective: You don’t need to pay for cloud-based API calls or subscriptions.
- Customization: You have full control over the model and can fine-tune it to suit your specific needs.
- Offline Access: Once installed, you can use the model without an internet connection.
Prerequisites
Before we begin, make sure your system meets the following requirements:
- Operating System: OLLAMA supports Linux, macOS, and Windows.
- Hardware: Running LLMs locally can be resource-intensive. A machine with at least 16GB of RAM and a modern CPU (or GPU for better performance) is recommended.
- Python: Ensure Python 3.8 or later is installed on your system.
- Storage: LLMs can take up significant disk space. Make sure you have at least 10-20GB of free storage.
Step 1: Install OLLAMA
The first step is to install OLLAMA on your machine. Here’s how to do it:
For Linux/macOS Users
- Open your terminal.
- Run the following command to download and install OLLAMA: curl -fsSL https://ollama.ai/install.sh | sh
- Once the installation is complete, verify it by running: ollama –versionYou should see the installed version of OLLAMA.
For Windows Users
- Download the OLLAMA installer from the official OLLAMA GitHub repository.
- Run the installer and follow the on-screen instructions.
- After installation, open Command Prompt and verify the installation: ollama –version
Or simple download it from here.
Step 2: Download Deepseek R1
OLLAMA supports a variety of pre-trained language models. For this guide, we’ll use the Deepseek R1 model, but you can choose any model that suits your needs.
- Open your terminal or Command Prompt.
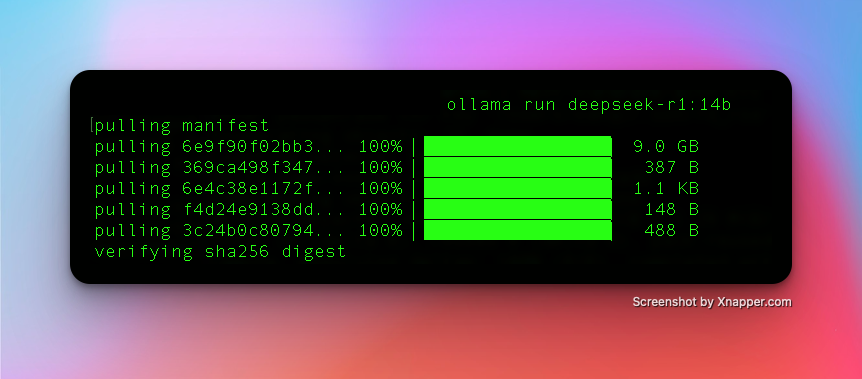
- Run the following command to download the Deepseek R1 model: ollama run deepseek-r1 This command will download the model weights and configuration files. Depending on your internet speed, this may take some time.
- Once the download is complete, you can verify the installation by listing the available models: ollama list You should see the Deepseek R1 model listed.
Step 3: Configure Deepseek R1
Before running the model, you may want to configure it to suit your needs. OLLAMA allows you to adjust parameters such as temperature, max tokens, and more.
- Create a configuration file named
config.yamlin your working directory. - Add the following content to the file: model: Deepseek-r1 temperature: 0.7 max_tokens: 100
- Temperature: Controls the randomness of the model’s output. Lower values make the output more deterministic.
- Max Tokens: Limits the length of the generated text.
- Save the file.
Step 4: Run Deepseek R1 Locally
Now that the model is downloaded and configured, it’s time to run it locally.
- Open your terminal or Command Prompt.
- Run the following command to start the model: ollama run deepseek-r1:1.5b This will load the model into memory and start an interactive session.
- You can now interact with the model by typing prompts. For example: Prompt: Write a short story about a robot learning to paint. The model will generate a response based on your input.
Step 5: Integrate the Model into Your Applications
OLLAMA provides an API that allows you to integrate the model into your own applications. Here’s how to set it up:
- Start the OLLAMA server by running: ollama serve
- The server will run on
http://localhost:8080. You can send HTTP requests to this endpoint to interact with the model. - Here’s an example using Python to send a request to the model. This script sends a prompt to the model and prints the generated text.
import requests url = "http://localhost:8080/generate"payload = { "prompt": "Explain the concept of quantum computing in simple terms.", "max_tokens": 150 }response = requests.post(url, json=payload)print(response.json()["text"])
Step 6: Optimize Performance
Running LLMs locally can be demanding on your hardware. Here are some tips to optimize performance:
- Use a GPU: If your machine has a compatible GPU, OLLAMA can leverage it for faster inference. Make sure you have the necessary drivers installed.
- Reduce Model Size: If your machine struggles with large models, consider using a smaller variant of the model.
- Adjust Configuration: Experiment with the
max_tokensandtemperatureparameters to balance performance and output quality.
Troubleshooting Common Issues
- Out of Memory Errors: If your machine runs out of memory, try reducing the model size or upgrading your hardware.
- Slow Performance: Ensure that your system meets the minimum requirements. Using a GPU can significantly improve performance.
- Installation Errors: If you encounter issues during installation, check the OLLAMA GitHub repository for troubleshooting tips.
Conclusion
Running a large language model locally using OLLAMA is a powerful way to harness the capabilities of AI while maintaining control over your data and resources. Whether you’re building an application, conducting research, or simply exploring the world of AI, OLLAMA makes it easy to get started.
By following this guide, you’ve learned how to install OLLAMA, download a language model, configure it, and run it locally. You’ve also seen how to integrate the model into your applications and optimize its performance. Now it’s your turn to experiment and unlock the full potential of LLMs on your own machine.
FAQs
Q: Can I run multiple models simultaneously using OLLAMA?
A: Yes, you can run multiple models by starting separate OLLAMA instances on different ports.
Q: Is Deepseek R1 free to use?
A: Yes, Deepseek R1 is open-source and free to use.
Q: Can I fine-tune a model using Deepseek R1?
A: Currently, Deepseek R1 focuses on running pre-trained models. For fine-tuning, you may need to use additional tools like Hugging Face or PyTorch.
Q: What other models are supported by OLLAMA?
A: OLLAMA supports a wide range of models, including GPT-J, GPT-Neo, and more. Check the official documentation for a complete list.
By following this guide, you’ve taken a significant step toward leveraging the power of large language models on your own terms. Happy coding!